Apache Kafka is an open source distributed streaming platform. It allows to publish/subscribe to data feeds (stream), it stores the data in a fault tolerant way and it allows consumers process the data as per the consumer’s need.
Key concepts in Kafka
It runs in a cluster, with configurable replication across the nodes.
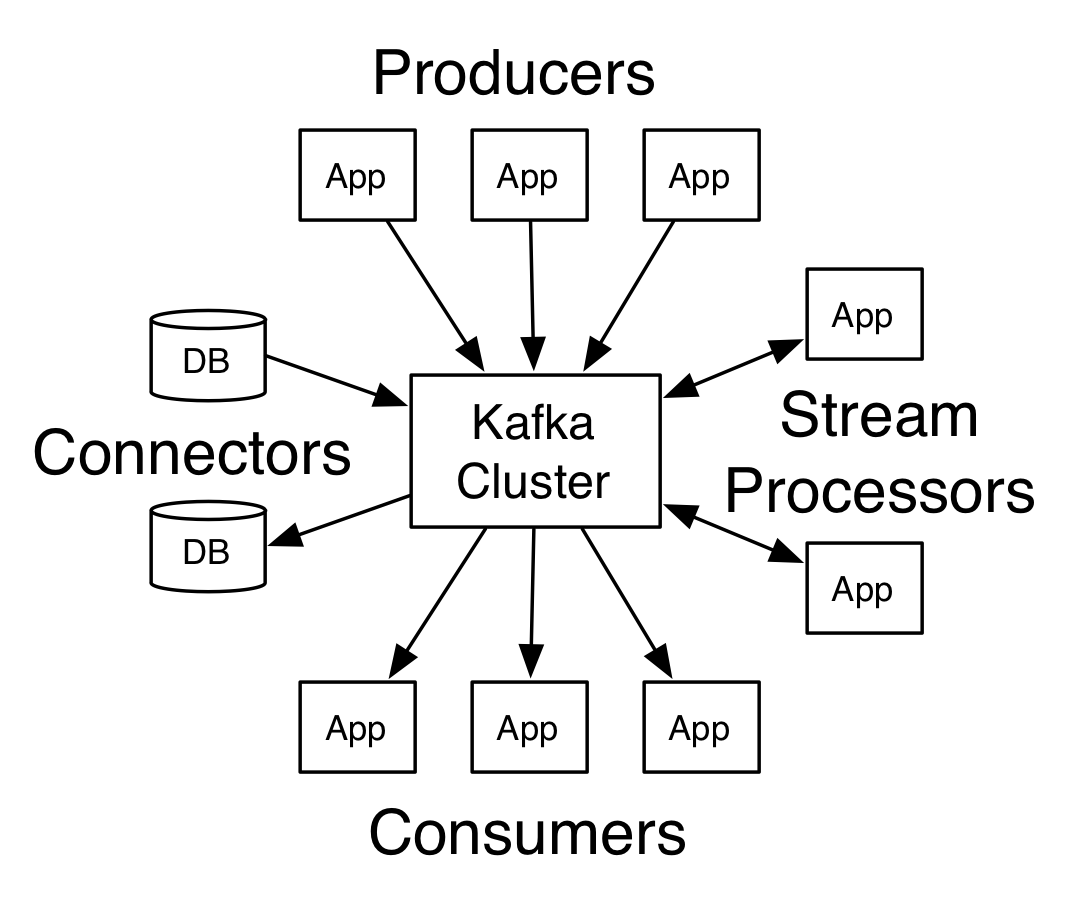
- Topics – These can be considered as message queues where publisher post their messages and consumers pick their messages.
- Record – each record consists of a key, value and a timestamp.
- Producer API – It allows publishers aka producers to post the messages or stream of messages to one or more topics in Kafka.
- Consumer API – it allows consumers to poll the topics and fetch messages. Consumers can subscribe to one or more topics.
- Stream API – it consumes the messages posted by publishers, processes them and posts the output messages back to Kafka system topics. Essentially they transform the messages.
- Connector API – These connect Kafka topics to various applications and/or data sources.
History of Kafka
This platform was originally developed by the LinkedIn team and was eventually made open source. It is written in Scala and Java language. This platform can be used as a storage system, messaging system or simply stream processing. It achieves high throughput and low latency by batching the messages to optimize the n/w overhead and by using Java NIO. At its core, Kafka uses a simple binary protocol over TCP to communicate amongst various components.
Guarantees given by the platform:
- Records will always appear in the same sequence in the queue as they were received from the producers
- A consumer will see the records in the same sequence as they appear in the queue
- A topic with replication factor N, will be usable up to N-1 server failures, without losing any data.
Sample use cases
- Message broker – can be compared with ActiveMQ or RabbitMQ
- Website activity tracking – pushing various data points and then writing consumers to process the data
- Log aggregation across various nodes
Related Links
Related Keywords
ActiveMQ, RabbitMQ, AMQP, Broker




