Folks working with Kubernetes would be able to relate to the word “K8ssandra” very quickly. Something related to Kubernetes (more fondly called K8s). Yes, that is right.
Apache Cassandra is a preferred database for many large-scale applications. Kubernetes has been providing orchestration tooling and infra for several of these applications. Combining these two under a single umbrella helps enterprises to meet their requirements easily.
What is K8ssandra?
It is a cloud-native distribution of Apache Cassandra that runs on Kubernetes. Pronounced as “kate”+”Sandra”, this is an open source project licensed under Apache Software License v2. This project provides a plethora of tools to provide data APIs and automated operations for Cassandra. This includes tools for monitoring, services for site reliability, and backup/restore tools.
Cassandra is a distributed database management system. It is a free and open source project that provides a scalable, highly available, fault-tolerant, column-oriented database to support large amounts of data across many commodity servers.
Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available. (Source)
Creating, deploying managing various components of Kubernetes structure such pods, deployments and ConfigMaps could be time intensive and complex. As your architecture grows, this becomes all the more difficult. However, K8ssandra does the heavylifting for you. And as a infrastructure engineer or even a developer, it is always better if you have a reliable tool who does that job for you.
Components
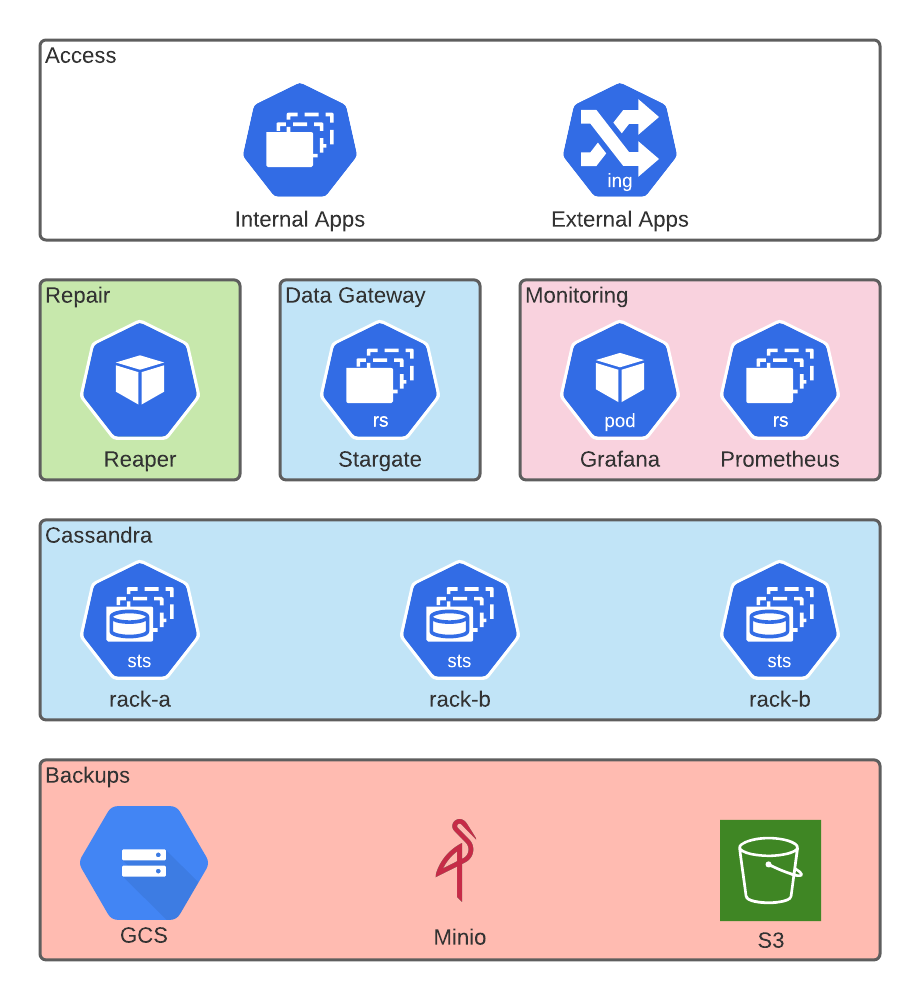
It provides a set of components which are glued together as part of the installation process itself. The following components are packaged and installed:
- Apache Cassandra
- Stargate
- Cass Operator
- Reaper for Cassandra
- Medusa for backup/restoration
- Metrics collector with Prometheus integration and visuals via Grafana
Resources:
