Everyone is aware of “cloud” now. The cloud provider sets up huge infrastructure and makes it available to their customers either as bare infrastructure or a managed service. In either case, it is a huge investment for the provider. All the servers, network bandwidth, and other resources are their inventory. As is the case with any business, idle inventory is a problem. And that is where Spot Instance comes into the picture.
Munin
You are a system administrator, managing a set of servers. As a part of your job, you need to ensure that all the servers are up and running 24X7, they are resources are utilized optimally. And that no single server is overloaded or consuming huge memory or some similar abnormal behavior over a time period. Obviously, you will be needing a monitoring tool. Munin is one such tool, which helps system administrators to keep track of system resources.
Munin Architecture
Munin derives its name from mythology. It means memory. This monitoring software memorizes what it sees and hence the name.
This monitoring tool uses Master-node architecture. Master periodically pulls data from all the configured nodes and processes it to create graphical dashboards.
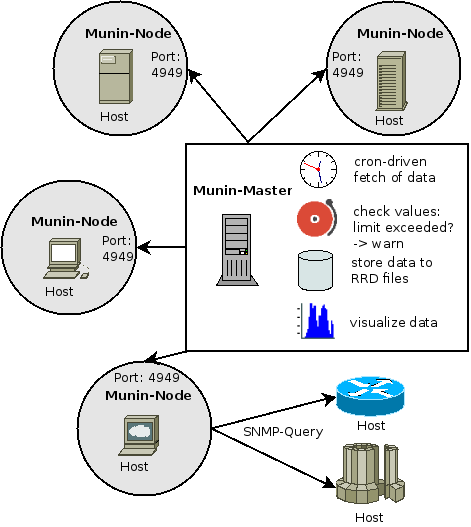
One of the advantages of Munin is its vast plugin eco-system. There are several hundred plugins available, which make it a powerful monitoring system. Munin itself uses RRDTool, which is written in Perl, whereas plugins could be written in any language. This tool is available on various distros such as Debian, Ubuntu, and CentOS.

Alternate Server Monitoring Tools
Several alternatives are available.
- Nagios
- NewRelic
- Netdata
- Zabbix
- …
Considering that most of the deployments are in the cloud these days, you may want to use the monitoring tools provided by your cloud providers:
- AWS Cloudwatch
- Azure Monitor
- Google Cloud – Stackdriver monitoring
Related Links
Related Keywords
Server Monitoring, AWS Cloudwatch, Azure Monitor, Nagios, NewRelic
Kubernetes
Kubernetes is a tool or a system for automating the deployment of containerized applications. In a loose analogy, one can say what Chef is for infrastructure deployments, Kubernetes is for container deployments.
History of Kubernetes
It was part of Google’s internal tool system called “Borg” which was later made as Open-source in 2015. Internal codename of this project was “Seven” and is reflected in the logo of this system.
Kubernetes has been maintained by Cloud Native Computing Foundation which is a collaboration between Google and Linux Foundation.
What does Kubernete offer?
It offers to manage the “immutable infrastructure” in an automated fashion. Typically, containers are launched using images which do not change. If you want to make changes to the software piece which is part of the container, you simply update the image, launch new containers and throw away the older containers. Kubernetes allows you to do this efficiently.
The lowest level abstraction that Kubernete provides is called a “Pod”. It consists of one or more containers which can run on a same “node”. A Node is a server or VM on which Kubernetes cluster is running. The containers in a Pod could be sharing resources and can communicate with each other. This allows running tightly knit services to be run from the same Pod.
In Kubernetes configuration, Pods are not updated but are simply destroyed. New Pods are created when any of the containers are required to be updated.
“Deployments” are something that runs the Kubernetes cluster. They store the configuration, dependencies, resource requirements and access etc. Kubernete also has a “ReplicationController” which allows you to replicate the Pods as per the need.

Leading cloud providers like AWS, Microsoft and Google provide the managed Kuberenets services viz Amazon Elastic Container Service (Amazon EKS), Azure Container Service (AKS), Google Kubernetes Engine(GKE).
Related Links
Related Keywords
Docker, Container, DevOps, Chef, Puppet
Tutorial
Serverless Computing
Serverless Computing is a computing model where servers are not used. Are you kidding me? You are right. This is not a case. Serverless Computing is actually a misnomer. What it really means is developers are freed from managing the servers and are free to focus on their code/application to be executed in the cloud.

So, how does Serverless Computing really work?
In this computational model, you only need to specify minimum system requirements such as RAM. Based on that the cloud provider would provision the required resources such as CPU and network bandwidth. Whenever you need to execute your code, you hit the endpoint and your code is executed. In the background, the cloud provider, provisions the required resources, executes the code and releases the allocated resources. This allows cloud provider to use the infrastructure for other customers when they are idle. This also gives out the benefit to the customers as they are not charged for the idle time. Win-Win situation for both, isn’t it?
Serverless Computing is popular in microservices architecture. The small pieces of code which form the microservices can be executed using Serverless components very easily. On top of it, cloud provider also handles the scaling up. So if there are more customers hitting your serverless endpoint, cloud provider would automatically allocate more resources and get the code executed.
Any precautions to be taken?
Absolutely. Every developer needs to keep few things in mind while developing code for Serverless computing:
- The code can’t have too many initiations steps, else it will add to the latency.
- The code is executed in parallel. So there shouldn’t be any interdependency which would leave the application or data in the incoherent state.
- You don’t have access to the instance. So you can’t really assume anything about the hardware.
- You don’t have access to local storage. You need to store all your data in some shared location or central cache.
So who all provide this option?
- AWS (obviously!!) was the first one to provide this (2014) – AWS Lambda.
- Microsoft Azure provides Azure Functions
- Google Cloud provides Google Cloud Functions
- IBM has OpenWhisk which is open source serverless platform
Support for languages varies from provider to provider. However, all of these offerings support Node.js. Among other languages, Python, Java are more popular.
Related Links
- Wikipedia
- AWS Lambda
- Azure Functions
- Google Cloud Functions
- Getting Started with Serverless Architecture – Slideshare presentation
Related Keywords
Serverless Architecture, API Gateway, AWS S3, Microservices Architecture
API Gateway
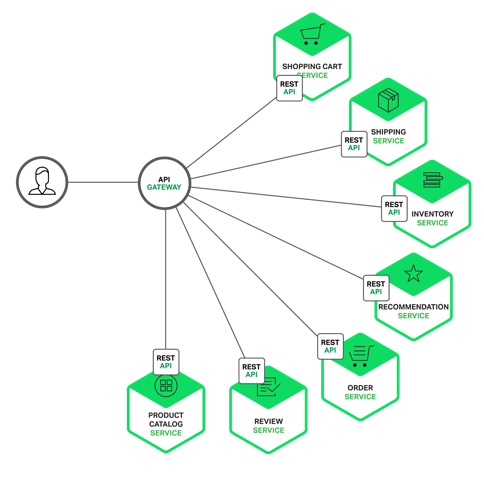
API Gateway is a server that is a single entry point to your system. As you can imagine, primary function of this server is provide various API endpoints to various clients. It also hides the backend services from the client.
Why should I use API Gateway?
Consider a complex architecture where variety of clients are accessing your system. In this age, monolithic applications are getting outdated whereas microservices based applications are popular because of their efficiency and maintainability. As a result, all of the clients will need to make several calls to get data from various services from your system. So even to render one page, client will end up making several calls. This would be a problem on mobile network, which typically has latency issues. To add to this complexity, each client could have their own requirements. That could also mean client specific code.
All these problems can be solved by implementing an API Gateway. This server provides single point of reference for all the clients. It detects the client and breaks the request into multiple backend requests to fetch the data. This gives additional benefit of consolidating responses from all the backend requests into single response for the client.
Are there any drawbacks?
Yes, as is the case with almost everything in life! If due care is not taken, API Gateway itself can become bottleneck and heavy. All developers would be required to update API Gateway whenever they make changes to the endpoints or protocol to access their respective services. API Gateway gathers data from multiple webservices. As a result, failure of even one service could lead to unavailability of entire service. Or it could add delays in response to the client.
However, there are already ways to counter these drawbacks. Proper process such as DevOps could lead to removal of API Gateway becoming developer bottleneck. Usage of circuit-breaker libraries such as Netflix Hystrix could avoid overall service breakdown even in case of partial service outage.
Reference Links:
Example Implementations / Providers:
- AWS API Gateway
- Azure API Management
- Vertx
- JBoss Apiman
Related Keywords
Microservices Architecture, AWS, Azure, Hystrix