Paravirtualization is a type of virtualization, which allows us to install and run one or more different operating systems (Guest OS) on a single physical server (Host OS). You might get tempted to compare it with Hypervisor and you wouldn’t be wrong. They have similarities and differences.
A Hypervisor is a software that allows installing one or more different operating systems on a single physical server. The OS which runs the Hypervisor is called as Host OS and the OS which is run by Hypervisor is called Guest OS. Here, guest OS doesn’t have a clue that it is running in a virtualized environment. This is where Hypervisor differs from Paravirtualization.
So how does Paravirtualization work?
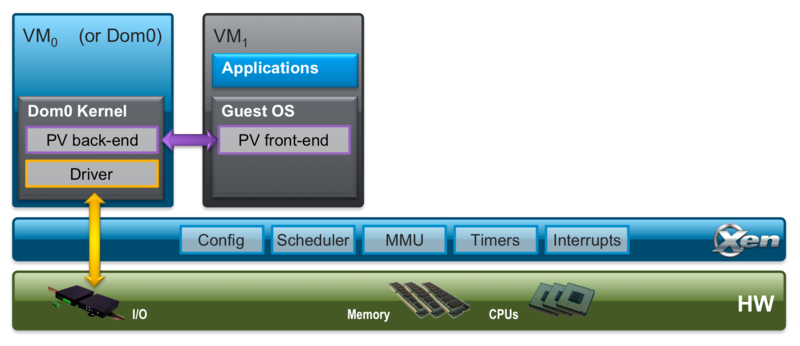
In virtualization, Hypervisor acts as a relay between guest OS and host OS. In Paravirtualization, guest OS needs to know that it is interacting with Hypervisor and hence needs to make different API calls. This calls for modifications to the guest OS and hence creates a tight coupling between guest OS and Hypervisor used. Since proprietary OS providers such as MS do not allow OS level modifications and hence you would end up using open source operating systems such as Linux. A good combination is Linux with Xen server
You would be wondering if there are any real advantages of paravirtualization. Paravirtualization has shown performance improvements for certain applications or in certain use cases, but it has not shown the reliability. Especially with the rise of software level virtualization, which shows very high reliability, need for Paravirtualization has gone down. The cost associated with guest OS modifications, tight coupling with Hypervisor, is not getting offset by the not-so-predictable performance gains. So, you wouldn’t find many instances where paravirtualization is used.
Related Links
Related Keywords
Hypervisor, Virtualization, Containers

