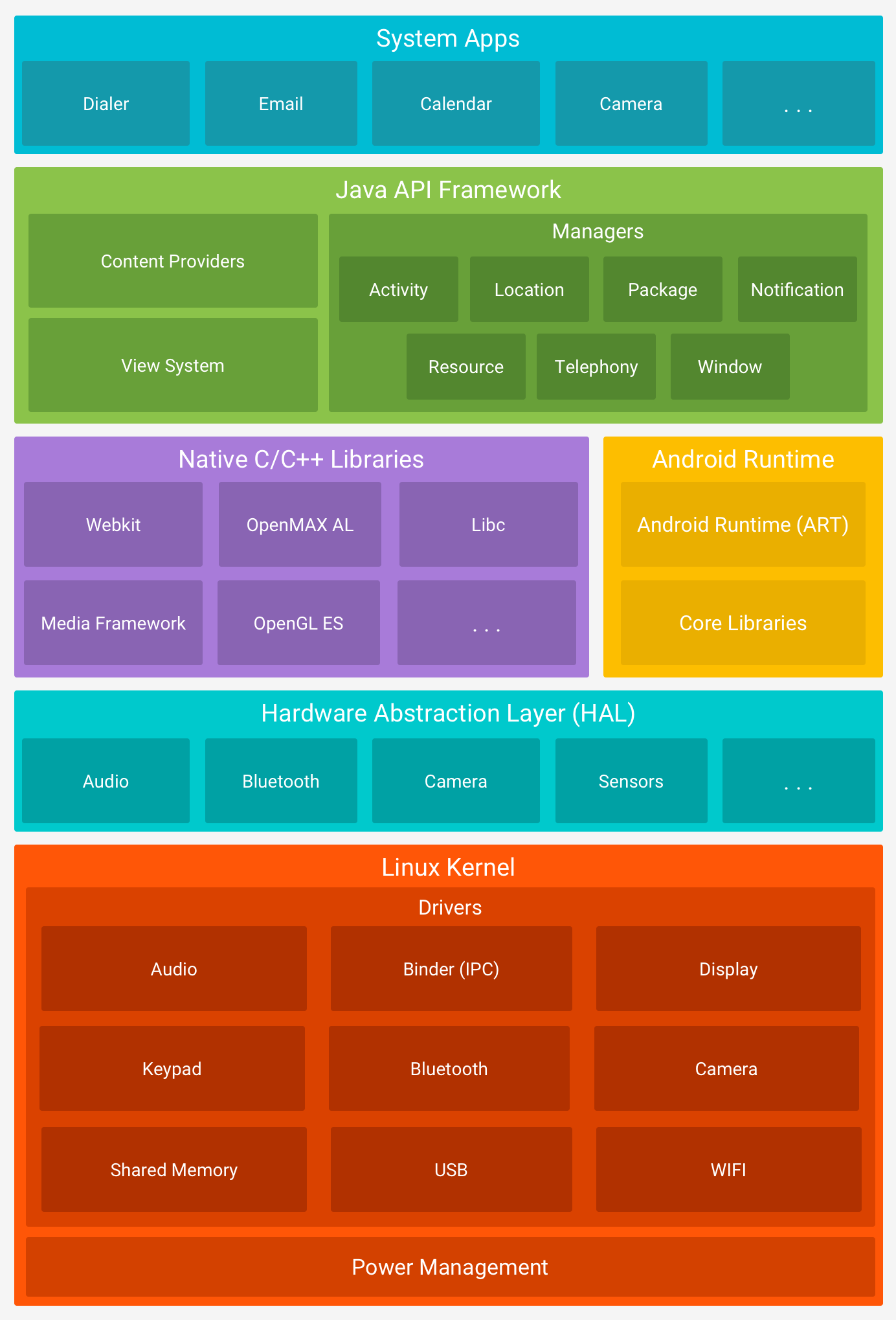
“Chef” is an automation platform for DevOps. It helps you manage the configuration of your server(s) in an automated fashion. The configuration includes pushing of certain patches or to push certain configuration files to a set of servers in your server farm. All such activities could be managed using this platform.

What problem does Chef solve?
As your infrastructure grows, it becomes difficult to maintain all the servers at all the times. You may have all your server on-premise (very rare these days), or completely on the cloud or a hybrid setup. Irrespective of the location of the servers, you would want all of them to be manageable. You would want to push changes to the configuration in a jiffy without worrying about how many servers you need to update. In case of 5-10 servers, you may want to do it manually. But as the number grows, this task becomes daunting. And this is precisely where Chef platform comes to the rescue.
How does Chef work?
Chef helps you look at your infrastructure as code! What does that mean? One can write what kind of configuration she wants on a given set of servers – this is known as a recipe. Each such recipe can be tested and pushed to target servers referred to as “nodes”. The recipe is then executed to update the server configuration as mentioned in the recipe. All this can be executed from a single machine – no matter what is the number of servers which need to be updated.
Each node registers itself with the Chef server and pulls the recipes which need to be executed on that node. Even after execution, it periodically checks with Chef server, if new recipes are available. This allows the administrator to push the changes in the configuration without having to log/connect to individual servers.
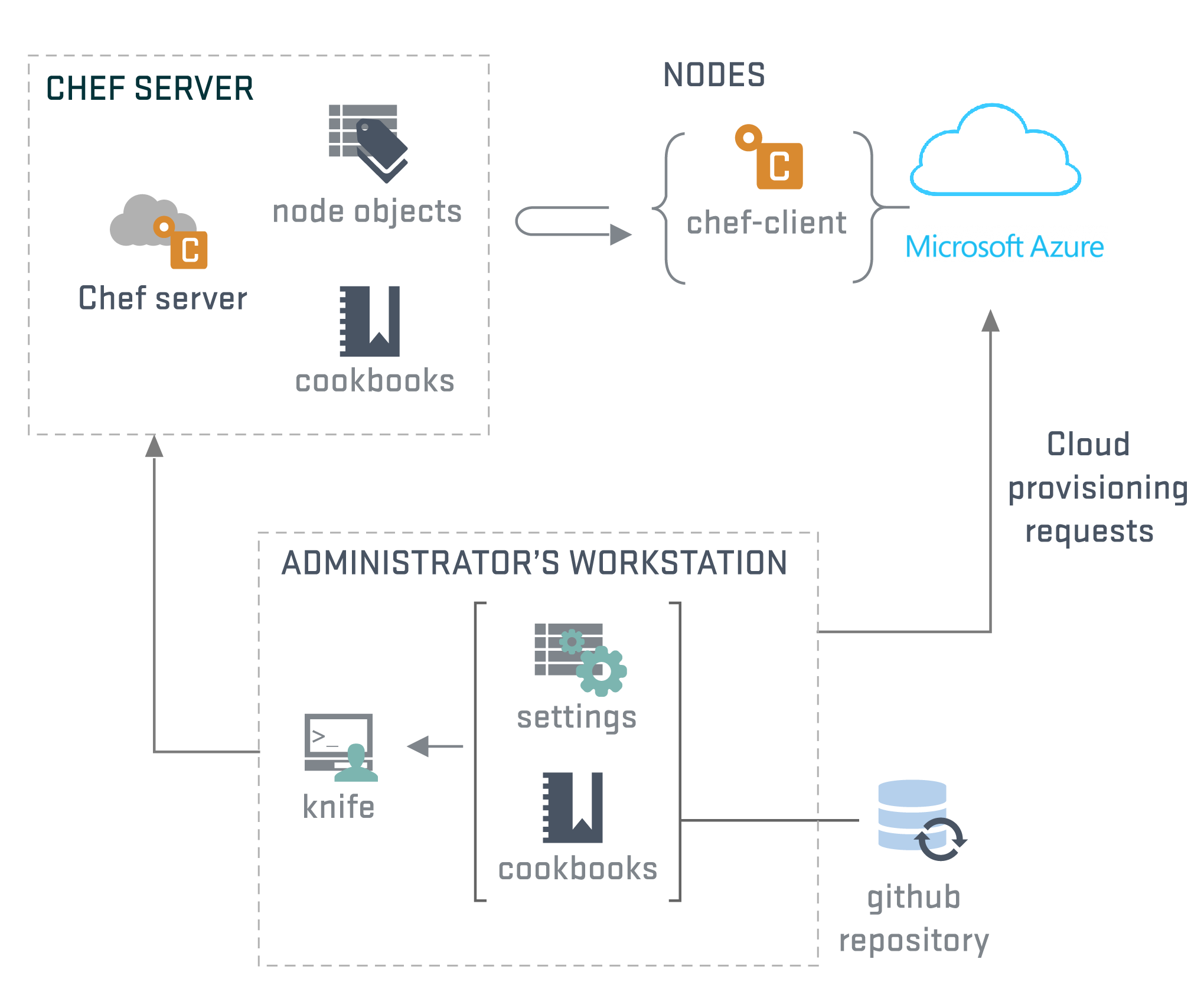
A collection of recipes is called as a cookbook. There are several such cookbooks are available out of the box or one can pick up a ready cookbook from the marketplace “Chef supermarket”. Of course, you can create your own recipes/cookbooks as well.
Chef has built-in support to build, test, and deploy the recipes. It also provides tools such as Chef Automate, which allows you to monitor and collect data across the servers from a single dashboard. It notifies you if any server is not as per the configuration so that you can fix it.
Because of such features, Chef forms one of the important portions of DevOps toolset.
Related Links
Related Keywords
DevOps, Puppet, Ansible, Saltstack, Fabric